I was talking with Diego Rodriguez a few weeks ago, who encouraged me to hack together a Segment Anything 2 implementation fulling using WebGPU. That's this!
It runs completely client-side, no data is sent to the server! You can read the source code here or try a demo at http://webgpu-sam2.lucasgelfond.online/.
I've been curious about some of the lower-level browser APIs (WebAssembly and WebGPU) since I started doing frontend, but haven't gotten much of a chance to play with them! The new model seemed like a great excuse to learn.
I started off looking a bit into the model, and trying to find some examples of people who'd gotten things working. Segment Anything 2 only came out a week or so ago, so most of the examples were for SAM-1. In web-sam and SAM-in-Browser others had used a small model called MobileSAM to do inference in the browser; it certianly seemed possible!
The common approach to running models in the browser is to use Transformers.js, essentially a JS port of the famous HuggingFace library. This was my initial approach, but it became clear the WebGPU support was quite poor, only available in an experimental v3 branch that was not yet released.
After getting my hands dirty getting some of the models up, I got an error that no backends were available; it turns out this is a common problem right now, as evidence by a huge GitHub issue about it. To summarize: use of WebGPU was not allowed in Chrome SerivceWorkers until April. We basically need to make use of ServiceWorkers to do inference not in the main thread, i.e. to not lock the user up.
Even after they were added to Chrome, support from ONNX Runtime, which Transformers.js uses under the hood, was spotty. In the aforementioned GitHub issue, users continued to discuss various patches to the runtime and Transformers.js, along with some stopgap solutions. I played with these (and even got a PR up on one) but realized it was simplest to just use ONNX Runtime. The runtime provides pretty good docs for using WebGPU environments.
A bug preventing use of WebGPU for these tasks was fixed just a few days ago; I'm using the August 4th dev build of the ONNX Runtime.
This is a pretty standard Svelte app, built to be simple, readable, and performant. I make a lot of use of a convention where new files are in their own folders, and we have an index within them, for easy navigation. It's fairly verbose, but I think it keeps the structure quite clean and easy to navigate, plus stops these files from being thousands of lines long.
My general structure pulls from web-sam, where the codebase is mostly divided between decoder and encoder. The encoding process essentially generates a set of features and image embeddings which are needed for creating the masks. The encoder also handles standard web actions, like the file drag-and-drop and selecting the model size.
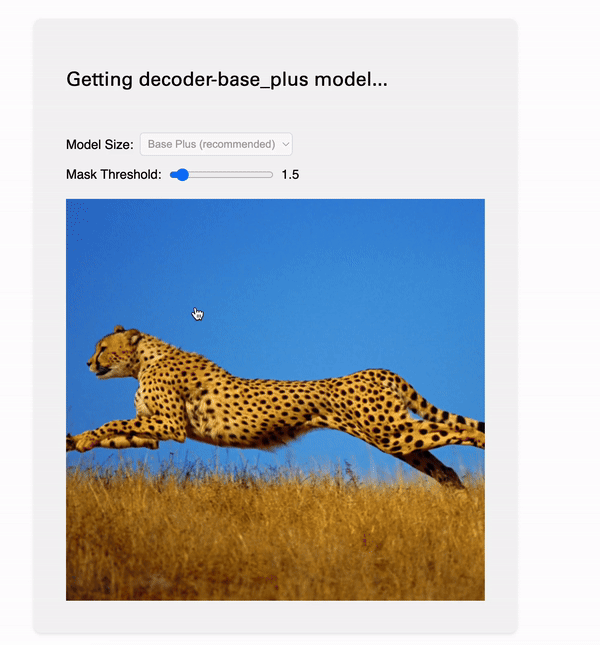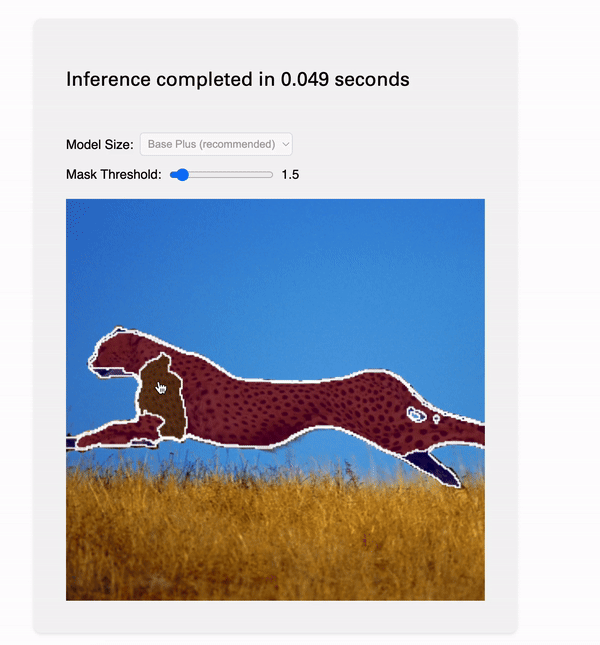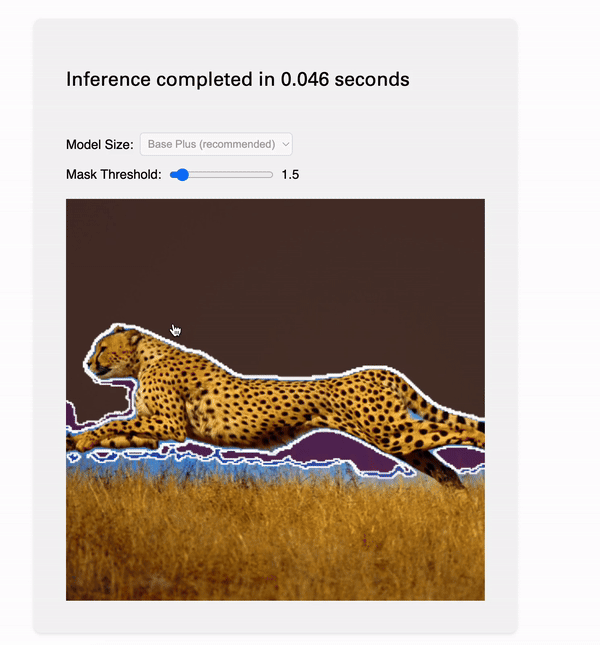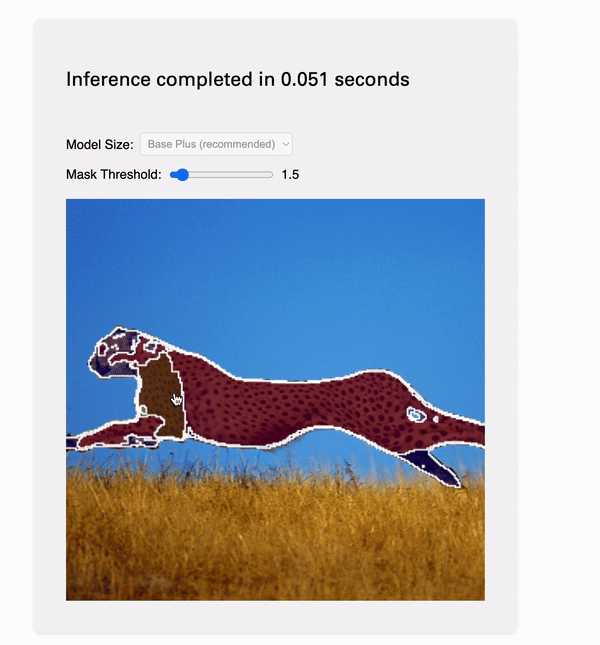
Every time a user clicks a point, we pass the point of their mouse and the results of encoding to our decoder. It will generate masks, which we display on the canvas. All of the HTML graphics things — adding the image, displaying the masks and contour (mask outline) are handled by special utilities in decoder/.
One of the more challenging engineering tasks here was getting the models to load properly; the encoders can exceed 200 MB, so GitHub/Vercel wouldn't handle them and I needed something else. Instead, I used BunnyCDN's 14 day free trial (LOL) and added extremely lax CORS policies so I could fetch from it.
I also build some caching logic to make these fetches only happen the first time. I store the models in the user's browser after first download. I'm using origin private file system which can save and access reasonably large files. My understanding, for example, Chrome will store up to 2 GB or 20% of free disk space (whatever is smaller) per website. In essence, given a model, we check to see if it is in the cache, and if not, we fetch it.
Because of the newness of the webgpu build of onnxruntime, building it is not well-supported. I burnt the better part of a day trying to fix Vite, which refused basically any imports onnxruntime-webgpu. I ended up just swapping to Webpack to make things simpler.
SAM-2's inputs and outptus vary a lot from SAM-1, so I spent some time building all of the pre-processing. For example: SAM 2 can only take 1024x1024 images as inputs and generate 256x256 masks, and its inputs / outputs are differently shaped than its predecessor.
Luckily, I found a great repo that uses the Python ONNX Runtime to run SAM2. Much of the time I'd simply work to translate the approach from the Python codebase in to JS efficiently.
This looked like: padding/cropping the inputs, normalizing pixel values, putting values into WebGPU tensors, scaling and smoothing the outputted masks, and displaying them properly on the HTML canvas. Cursor and Claude 3.5 Sonnet were of great help here, as well, in working with some of this syntax I'm less familiar with.
Model inputs certainly caused me the most initial confusion; my image would show up with a 3x3 grid of the same mask! It turned out this was just because of the way I pre-procssed the images, see below:
I also had to pretty heavily process the models to get them to work. First, I downloaded the checkpoints from Facebook Research. Then, I needed to convert them to .onnx format to be compatible with the runtime, which, luckily, was already exists in samexporter. I then used the ONNX Runtime's builtin runtime optimizer to convert the encoder models to .ort format for use on the web. (Note: my laptop crashed when trying to convert the large model so: no large model for now!)
I knew I wanted a few things:
That said, there's a lot more I'd like to build:
scripts/clear-opfs.js), but it is not exposed to non-developers.Overall this was a blast to learn!