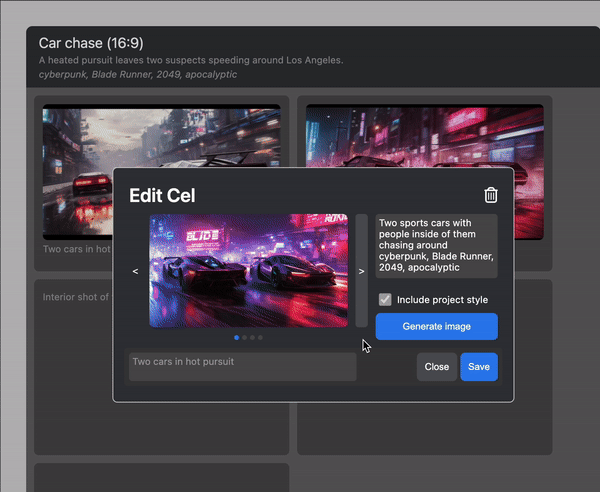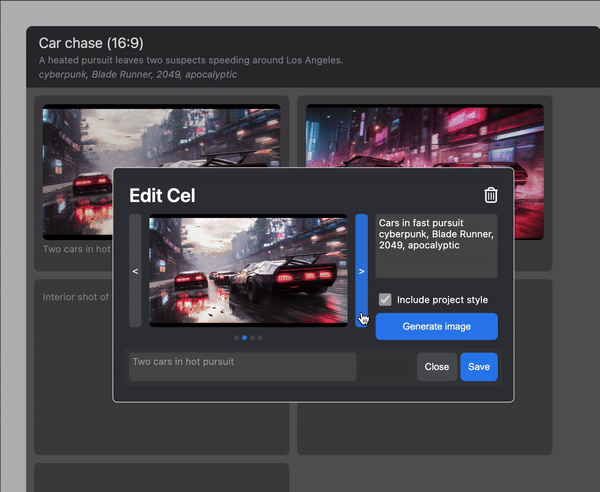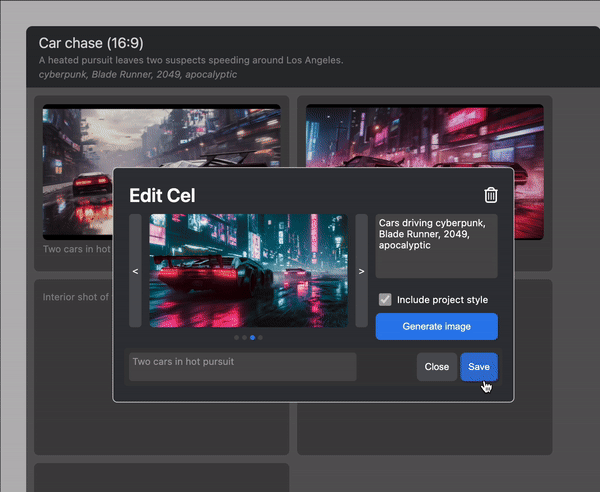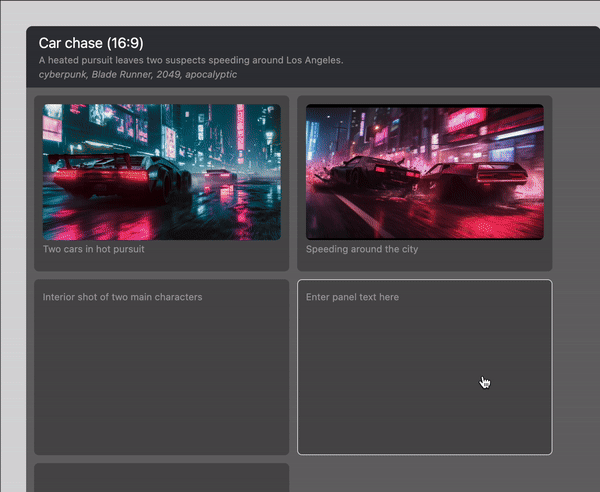
I've been working, most recently, on a tool to let artists make storyboards and shotlists with diffusion models. You can view a working production version of it here!
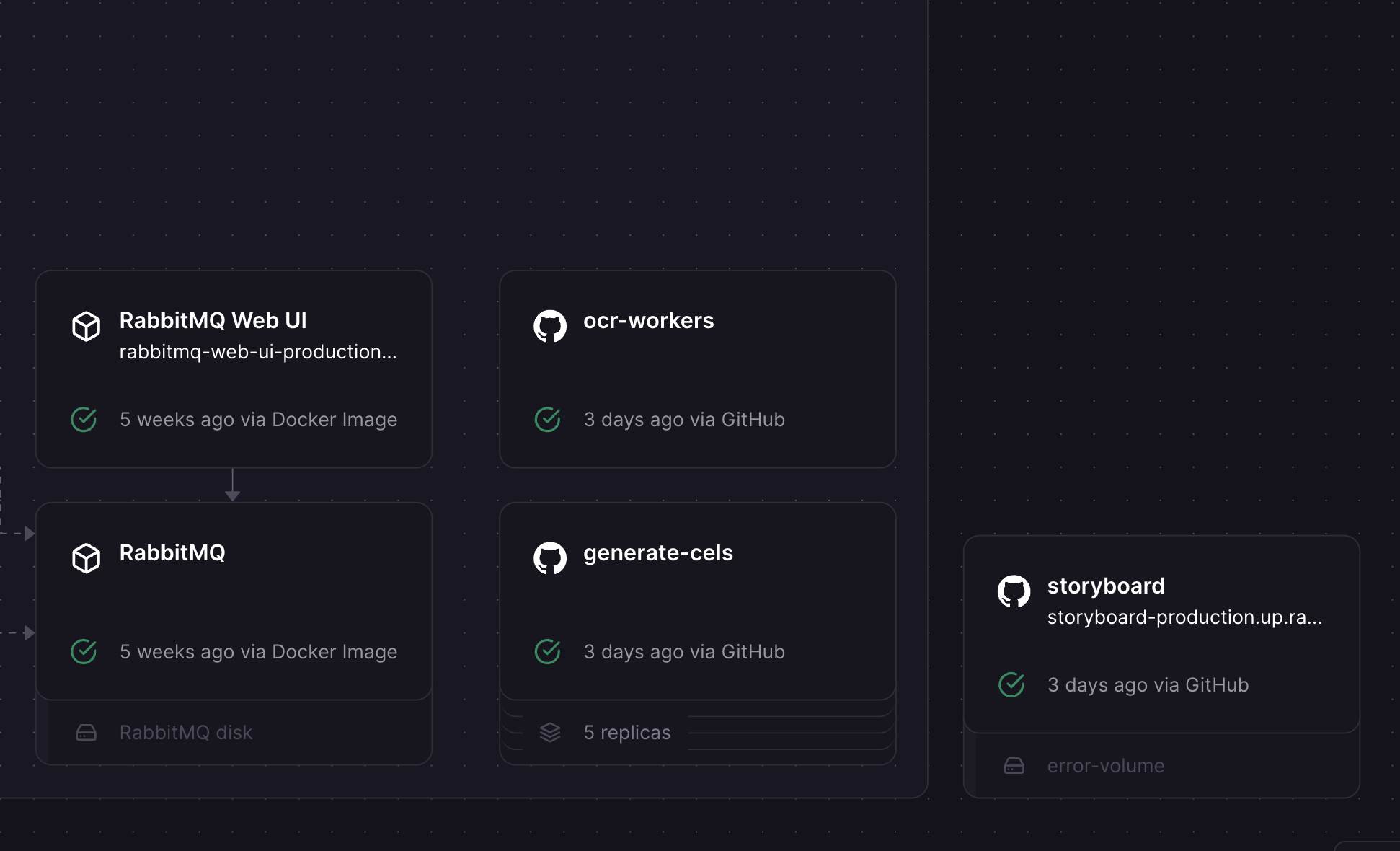
It's built with a fairly standard stack: Next/React/TS/styled-components for the frontend, hosted on Vercel. Most backend functionality (including auth) is handled by Supabase, but I also have a Node/RabbitMQ backend hosted on Railway for some of the more complex tasks: OCR-ing scripts (handled with RabbitMQ for each page/using Tesseract.js), generating shotlists from script text (hitting OpenAI's API), generating images (with Stability AI's API), and caching/delivering images (with Cloudinary).
I learned a ton of new technology for this; I'd never worked with diffusion models or NLP, Supabase, RabbitMQ, or Railway. Generally my approach was just: learn exactly what I need to in order to build functionality.
It was incredibly rewarding to build a software product completely myself: this is 100% my designs, frontend, backend, etc. I'm really pleased with the result!
I'm increasingly drawn to ways technology changes art production. More specifically: I'm most interested in art that emerges from recent technical breakthroughs. At Brown I designed a whole concentration around this (on top of my CS degree) called Art and Technology. One of my favorite examples was that of Ken Knowlton and Lillian Schwartz who, together, produced some of the first examples of computer film. They worked at Bell Labs, experimenting with new mainframes like the IBM 7094, with breakthroughs in computer graphics allowing for the Stromberg-Carlson SC-4020 microfilm plotter. Pixillation (1970), one of their most famous works, contrasts computer-generated patterns (made with the BEFLIX animation language) with hand-painted frames and film of natural crystal formations.
This was very much in my mind when I went home to Los Angeles for my spring break. I went to see a movie (Ex Machina, ironically) with an old friend, Jack, now a film director. He talked animatedly about how he'd been making lots of concept art and storyboards with Midjourney, and how helpful it was as a creative tool. He'd talked about it with some friends and professors in film school but none of them got it; the tools were too complex and weird to use.
A few weeks later, sitting in a lecture, an idea struck me. This is a great place to build software: to act, like Knowlton, as a translation layer between creatively-minded artists and technical breakthroughs. It would be incredibly interesting (and useful!) to build an interface for working with these new models that targets new people.
During that lecture, I began scribbling in my notebook, mocking up a few of the screens and a data model for the first version:
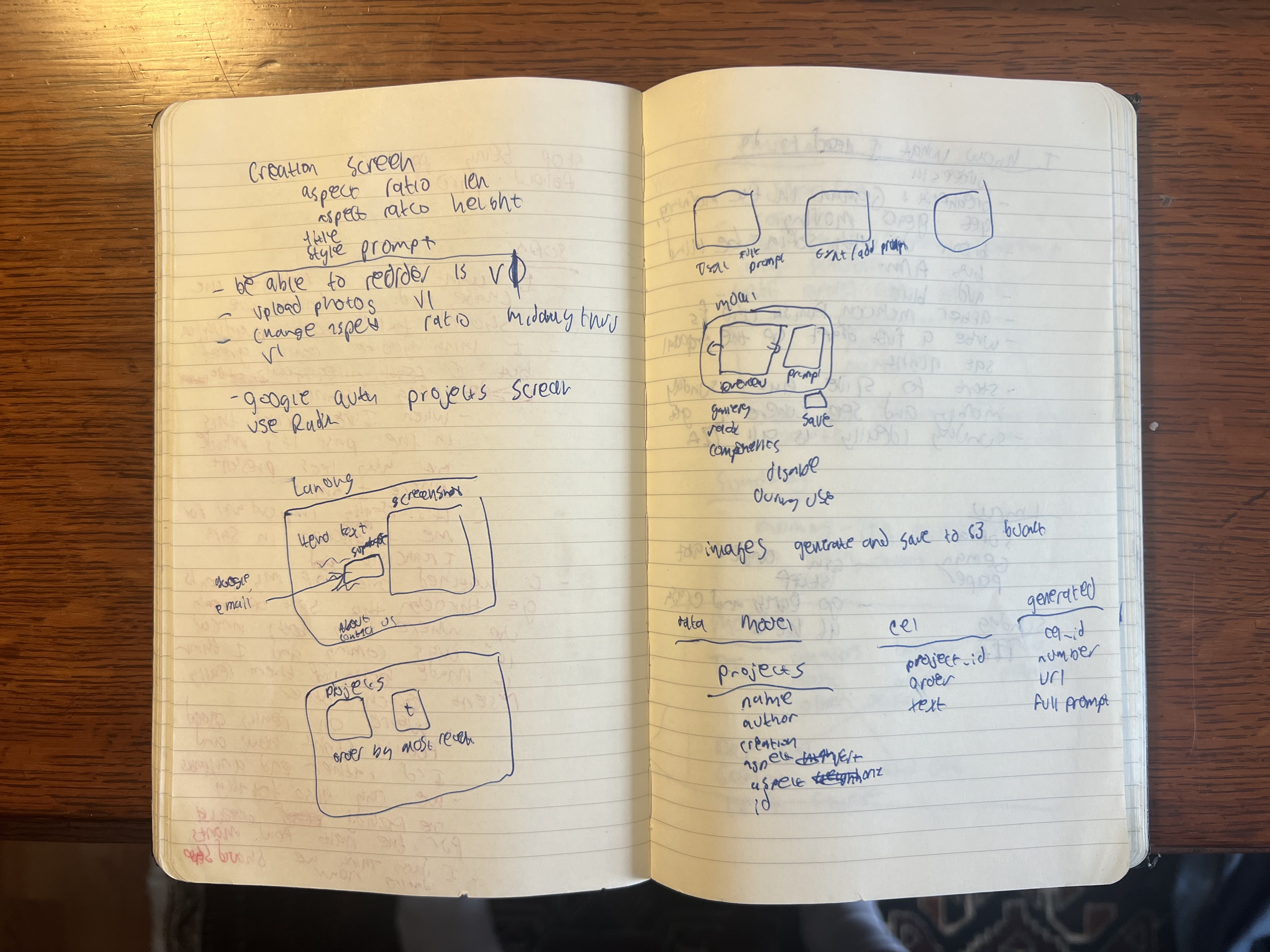
For my first version, I hacked together a few screens: project creation, image generation, and a way to organize panels. I haven't made movies in years, so I immediately wanted to talk to some folks closer to the problem. So, when I was home in LA, I printed out a few hundred posters asking for beta testers. I recruited my friends and family members to help post them all over Los Angeles, on trashcans, street signs, and wherever we thought they'd be seen.


I was pretty shocked by the enthusiasm from a totally random sign, I got about 40 responses on my form, all of whom I followed up with:
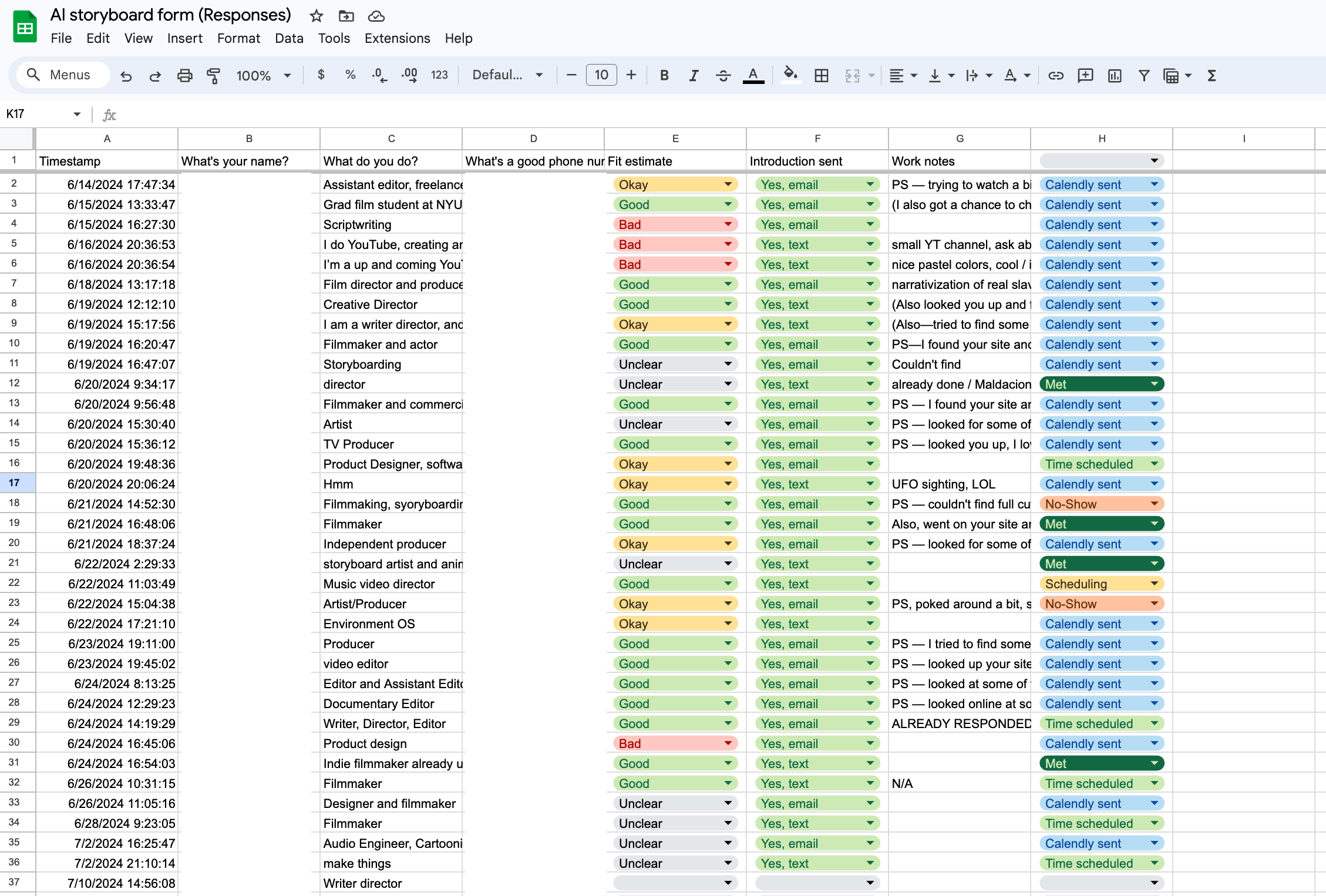
After talking with a few people, one of the most requested features was to input a script and have it pre-populate a shotlist with images. This was much more complex than anything I'd built before, but I designed a nice pipeline to handle it.
First, I prompted users to upload a script, in the project creation UI:
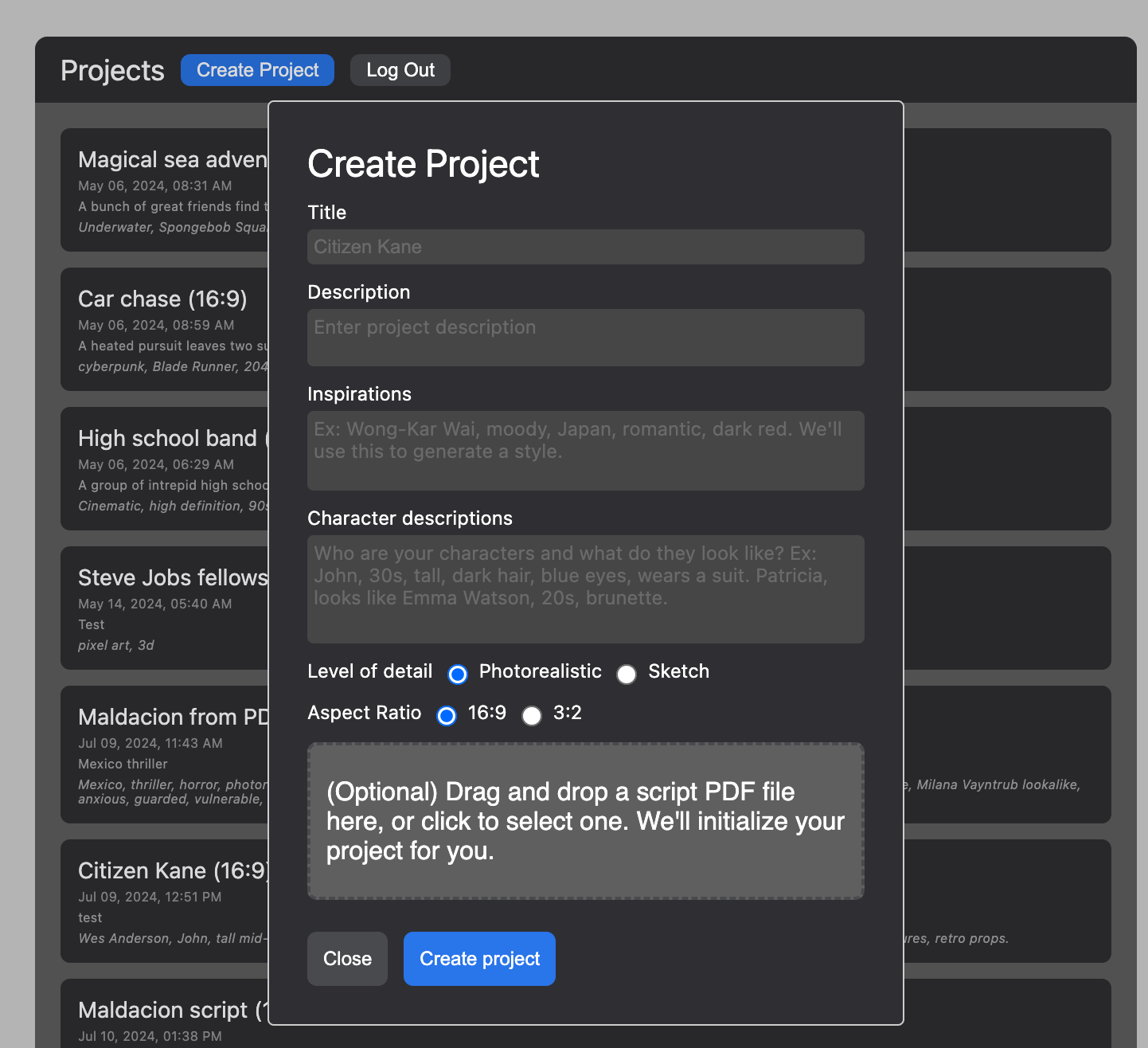
If they did, I'd upload this PDF and save it to Cloudinary, for future debugging. Then, using pdfjs, I'd split it into individual images, and also save these to Cloudinary. Then, I created a RabbitMQ sender which would queue up each image for OCR-ing, and a RabbitMQ reciever that used Tesseract.js to get text from each page. I'd save the results of each page to the database, and when each was complete, join the results together in order to get the full script text.
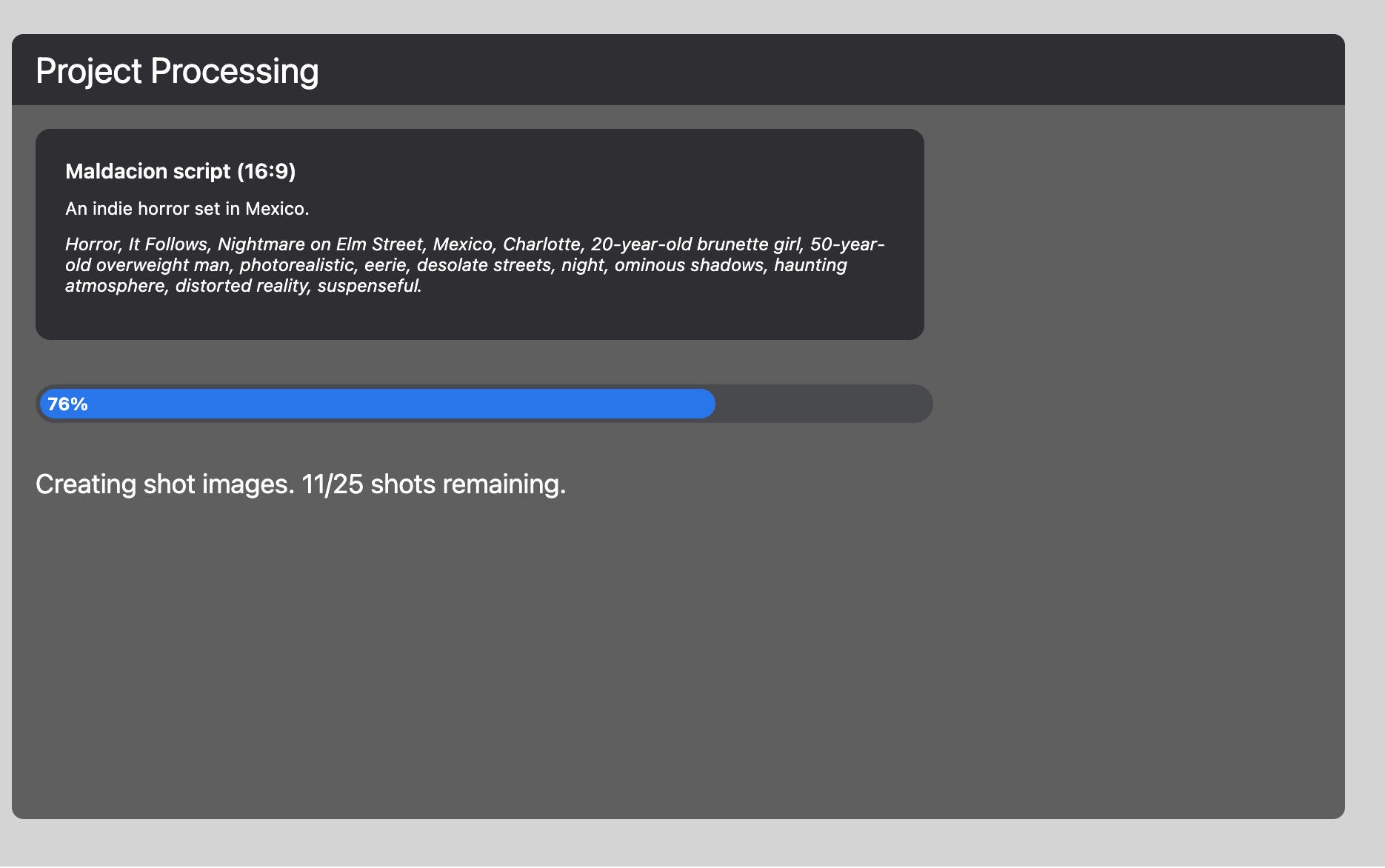
Then, I'd send the full script text to OpenAI's API, with some specific prompt instructions, to get things like location, time of day, and characters, for each shot. I'd then make sure this was in JSON, and, using another RabbitMQ sender, send out each panel to be generated, including both a prompt and a caption. Another RabbitMQ sender would dispatch all of these, which would be handled by a bunch of RabbitMQ recievers. Railway was great for this, because I could easily spin up 25 replicas to increase the speed of generation.
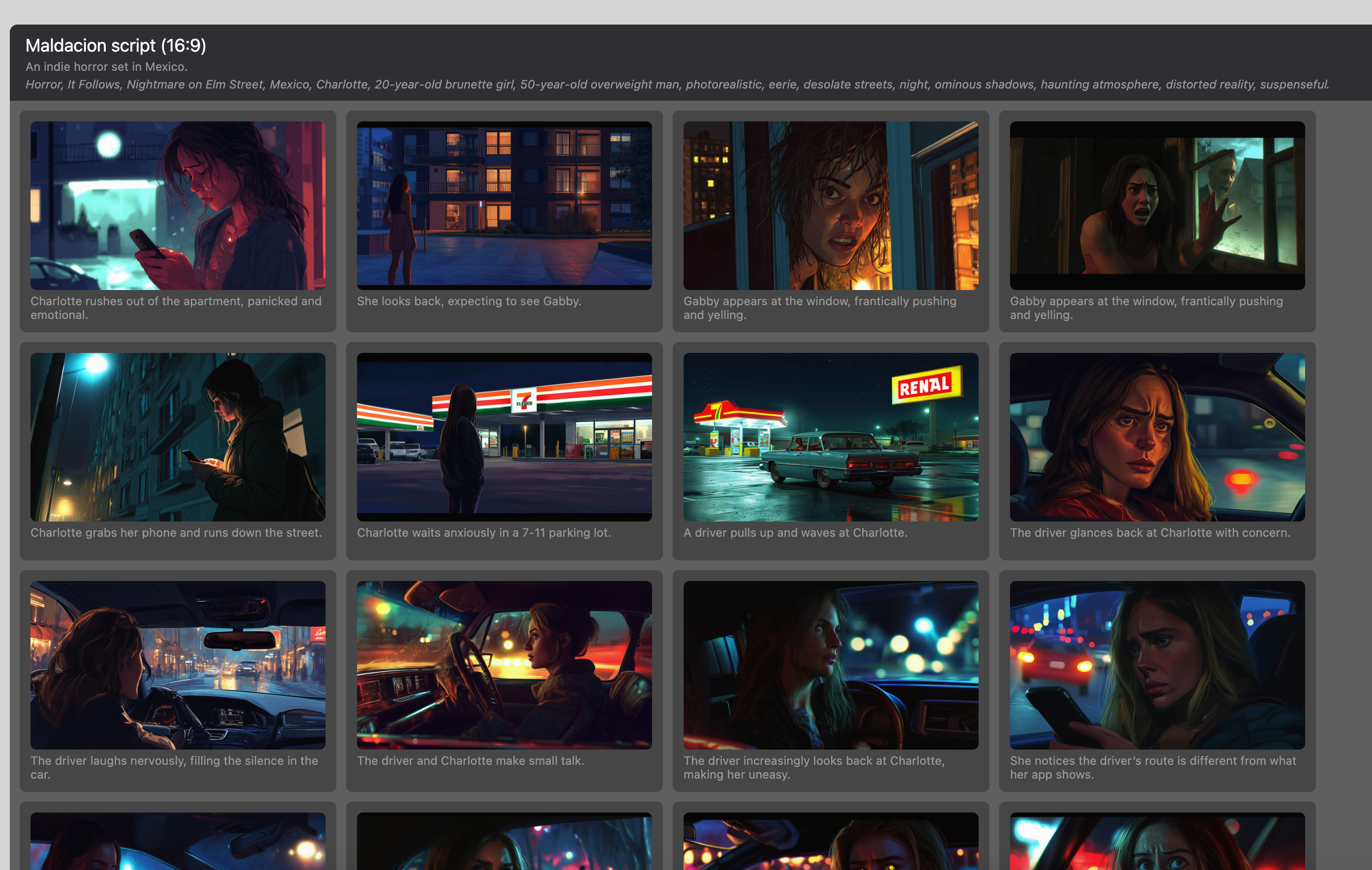
The results were quite impressive: these are the generations from a script input, with no additional processing or input:
I'm still working on this, slowly iterating on some other things folks have asked for like novel view synthesis and character consistency. More to come! I'm quite proud of a lot of the engineering here — code available on request.