Lesson #7: Collaborative filtering
This lesson is basically divided into two pieces.
The first half of the video is about various DL techniques. There's interesting stuff about optimizing runs on hardware: gradient accumulation, GPU memory usage, etc. There's also an explanation of cross-entropy loss, and of ensembling.
The second half is basically a rehash of the book's Chapter 8, on collaboartive filtering. They build a project using the IMDB dataset; I decided to use the UCSD "Goodreads" dataset. There's a version of it that is pre-processed on Kaggle but I had to do some of my own work to correlate book titles to book IDs. Anyways, you can see the notebook here
My results weren't amazing, which I suspect is because the data was fairly sparse (re: not a lot of users who reviewed many of the same books), but interesting loops:
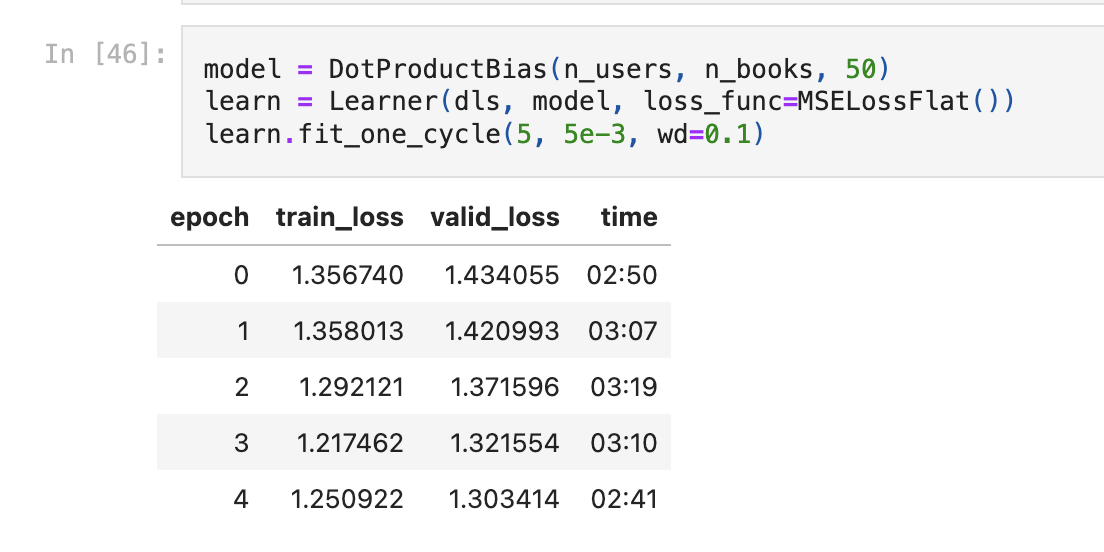
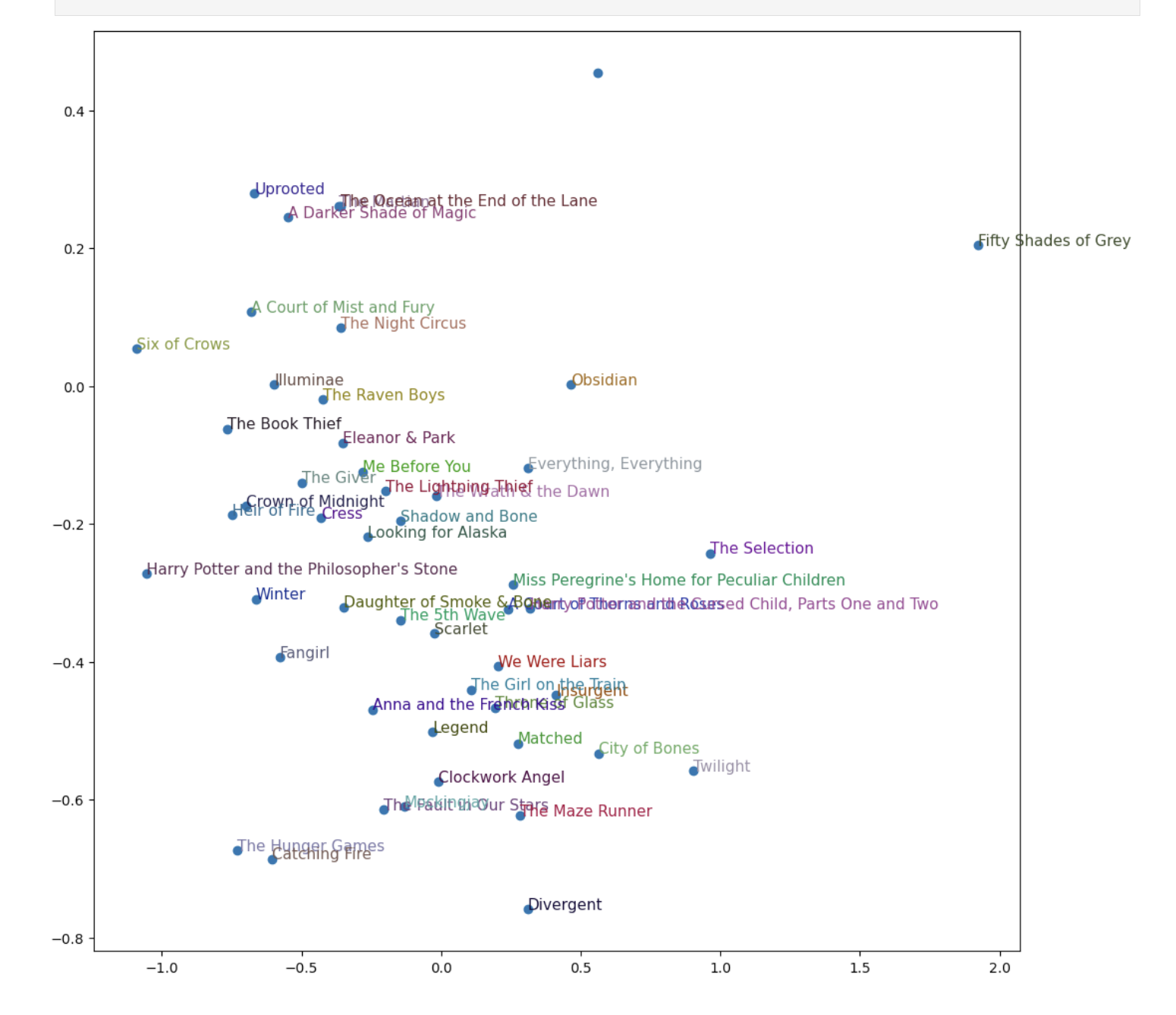
More interesting, of course, was principal component analysis that found just how popular Fifty Shades is:
Here's the questions from the lesson — I read this awhile ago so I forget many of them. Anyways: next is CNNs and then I'm done with Part 1!
- ✅ What problem does collaborative filtering solve?
Reccomendation for users (NIT: typo and based on interests of others)
- ✅ How does it solve it?
Take tons of ratings from tons of users. Have a set of latent factors for each item and each user. Initialize these latent factors randomly, and then train a model that sets the latent factors such that the dot product of the item factors and the user factors is predictive of their ultimate rating. If we can do this, given an arbitrary user and arbitrary item, we can predict how much they will like it.
- ✅ Why might a collaborative filtering predictive model fail to be a very useful recommendation system?
One set of users might overrun the site, i.e. people who are extremely enthusiastic abotu anime, even though that's a very specific and self-contained niche. There can also be filter bubbles from this, where the sort of content a site shows to its users helps to form the users that continue to come, etc. (NIT: not enough data also)
- ✅ What does a crosstab representation of collaborative filtering data look like?
A matrix of users and items, and what each user rated those items. This is likely to be extremely sparse except for some of the most common items and most active users.
- ✅ Write the code to create a crosstab representation of the MovieLens data (you might need to do some web searching!).
from ChatGPT
crosstab = pd.crosstab(index=ratings['userId'], columns=ratings['movieId'], values=ratings['rating'], aggfunc='mean')
- ✅ What is a latent factor? Why is it "latent"?
Some factor that represents some quality about an item. It's latent because it doesn't actually correspond to an actual component. I.e. rather than the specific 'sci-finess' or 'drama' of a movie, these factors are just whatever is most predictive. (NIT: key idea is that they are not explicitly given ,but learned! )
- ✅ What is a dot product? Calculate a dot product manually using pure Python with lists.
The result of multiplying two vectors together. I believe this would be something like;
list1 = [1,2,3]
list2 = [4,
5,
6]
dot_product = list1[0] * list2[0][1] + list1[1] * list2[0][1] + list1[2] * list2[0][2]
NIT: i could do with a list comprehension, too
- ✅ What does
pandas.DataFrame.mergedo?
Add columns from one dataframe to another, based on common ids. This is like the join command in SQL.
- ✅ What is an embedding matrix?
A matrix that keeps track of various items and their latent factors.
- ✅ What is the relationship between an embedding and a matrix of one-hot-encoded vectors?
A one-hot vector is basically a ton of 0s and a 1 in the palce we are looking for - basically, if we multiply by a one-hot vector, the result of the dot product is the value. (NIT: "equivalent to indexing")
- ✅ Why do we need
Embeddingif we could use one-hot-encoded vectors for the same thing?
The one-hot vector approach is really inefficient and Embedding optimizes it.
- ✅ What does an embedding contain before we start training (assuming we're not using a pretained model)?
Random numbers.
- ✅ Create a class (without peeking, if possible!) and use it.
class TestClass:
def __init__:
def forward(self):
- ❌ What does
x[:,0]return?
Assuming c,r: the first column of a datset. (NIT: "the user ids" (too nonspecific of a question, I think, in my defense! ))
- ✅ Rewrite the
DotProductclass (without peeking, if possible!) and train a model with it.
I did this, basically, in the notebook. Without looking, though, we are initializing the latent factors for the item and user plus biases for both. A forward pass finds the dot product and calculates the loss, updating the weights based on LR.
- ❌ What is a good loss function to use for MovieLens? Why?
Remember this was in the book but don't remember what it was!
EDIT: Mean-squared error!
- ❌ What would happen if we used cross-entropy loss with MovieLens? How would we need to change the model?
I also don't remember!
EDIT: need to output five predictions and calculate them!
- ✅ What is the use of bias in a dot product model?
In the example of movies: some movies are just better rated than others, some users are likely to rate movies more highly - this takes advantage of it!
- ✅ What is another name for weight decay?
L2 regularization?
- ❌ Write the equation for weight decay (without peeking!).
I don't remember the notation but the TL;DR is to penalize additional / complex weights.
NOTE: loss_with_wd = loss + wd * (parameters**2).sum()
- ❌ Write the equation for the gradient of weight decay. Why does it help reduce weights?
Don't remember. But: penalizes overly-specific weights that come from overfitting.
NOTE: 2*wd*parameters
- ✅ Wha Why does reducing weights lead to better generalization?
Prevents overfitting. NIT: reduces "sharp surfaces"
- ✅ What does
argsortdo in PyTorch?
Give the indices resultign from sorting data.
- ✅ Does sorting the movie biases give the same result as averaging overall movie ratings by movie? Why/why not?
Different — bias is more complex, and takes into account the preferences of all of the users vs. other movies, rather than just average. This is because we are determing how much bettet the movie does that we'd predict with just its latent factors, rather than just taking the average.
- ❌ How do you print the names and details of the layers in a model?
Don't remember
NOTE: type learn.model
- ✅ What is the "bootstrapping problem" in collaborative filtering?
Initial results are self-reinforcing, I believe. Without a lot of data recommendations are low quality, etc. Sorta: note, better answer is it's tough when there's nmot a lot of data
- ✅ How could you deal with the bootstrapping problem for new users? For new movies?
Ask users for their initial preferences in onboarding, fill in each user with an average user, etc. For new movies, same thing, could initialize to an average of the site or to the first few ratings.
- ✅ How can feedback loops impact collaborative filtering systems?
They can create filter bubbles for individual users but also change the sorts of useres who are attracted to the site.
- ❌ When using a neural network in collaborative filtering, why can we have different numbers of factors for movies and users?
Don't remember.
NOTE: concatenating the mebedding matrices
- ❌ Why is there an
nn.Sequentialin theCollabNNmodel?
Don't remember.
NOTE: couiple multiple nn.Module layers together
- ❌ What kind of model should we use if we want to add metadata about users and items, or information such as date and time, to a collaborative filtering model?
Don't remember.
NOTE: should use a tabular model instead!