Lesson #4: Natural Language Processing
(NOTE: this first appeared on Substack here)
Here we’re beginning to get into territory I haven’t really seen before—as much as I see about NLP on Twitter and play with the models, I’ve never implemented most of this myself.
Most of the lesson is focused on a Kaggle notebook about patent similarity. Jeremy goes into a bunch of fundamentals: tokens and tokenizers, and how to use the HuggingFace Transformers library. There’s a notebook he links to called “Getting started with NLP for absolute beginners” that is mostly used within.
I watched the video and ran the notebook cells, without too much issue beyond some standard debugging. I (quickly) read through two of the blog posts he linked throughout: one about the problems with metrics which was fairly self-explanatory, and another about making validation sets, which was mostly covered in the video.
Chapter 10 in the book is not particularly of note—it’s quite different from the video, because it’s using fast.ai’s API instead of Transformers. There’s, basically, a few more details about fine-tuning models, and that’s about it, feels pretty redundant with video + Kaggle “NLP for beginners” notebook.
Jeremy mentions that the best way to learn all of these concepts is to repeat the same process on a different dataset. I found a post about beginner-friendly NLP datasets and picked out one for sentiment analysis on COVID tweets.
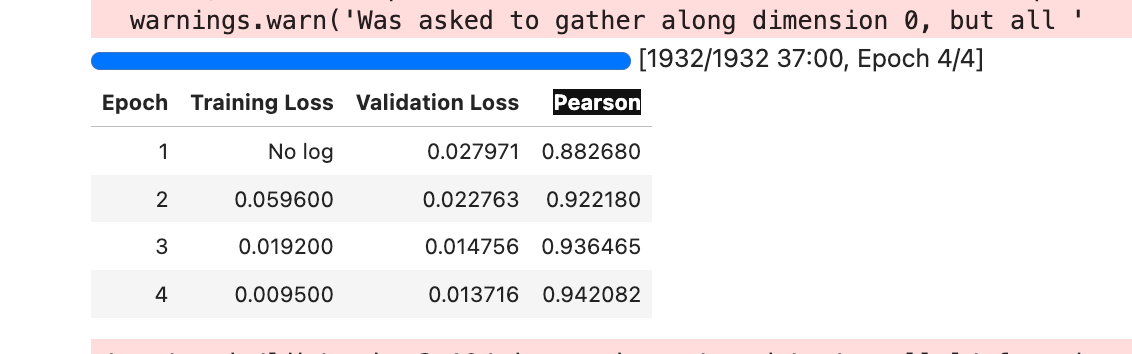
The process was pretty simple—my only real changes were needing to calculate the maximum length and add padding/truncation for tokenization (this is actually covered, a bit, in the book, which I discovered after reading). There were a few customizations for the specific dataset, the most significant change being converting text sentiment labels (“Extremely Positive”, “Positive”, “Neutral”, etc) to scalar values (1, 0.75, 0.5, etc).
My training went quite well and evaluated to about 94% accuracy for sentiment analysis:

You can see the Kaggle notebook I worked in here.
Here’s my answers for Chapter 10, which I sorta sped through:
Questionnaire
- ✅ What is "self-supervised learning"?
learning that doesn’t require categories, i.e. the category is taken from the independent variable (like - you just give a huge corpus of text without labels)
2. ✅ What is a "language model"?
seems very broad as a question - an ML model that works with text? (NIT: predict next word of text)
3. ✅ Why is a language model considered self-supervised? because it doesn’t need pre-labeling
- ✅ What are self-supervised models usually used for?
next word prediction (NIT: yes, autocomplete, but often also as a base for fine-tuning)
5. ✅ Why do we fine-tune language models?
because it takes lots of data to train for general english understanding and then less computation to get something that is well-suited for a specific dataset. we can just tune the last layer or similar
6. ❌ What are the three steps to create a state-of-the-art text classifier?
get another model
tokenize your data
train?
NOTE: train language modelon large corpus, fine-tune on text-classification dataset, fine-tune as text-classifier
7. ✅ How do the 50,000 unlabeled movie reviews help us create a better text classifier for the IMDb dataset?
we build something that is better at dealing with movie review-like text / learns context-specific terms i.e. cinematographic techniques or actors (NIT: “language style and stucture)
8. ✅ What are the three steps to prepare your data for a language model?
tokenize it
numericalize it?
batch it? (NIT: language model data loader)
9. ✅ What is "tokenization"? Why do we need it?
splits text up into words, or subwords. sometimes also splits up punctuation. allows the computer to form a dictionary / deal withw ords as numbers
10. ✅ Name three different approaches to tokenization.
split by word
split by subword
get rid of words that arent’ mentioned >3 times (NIT: character based tokenization) 11. ✅ What is
xxbos?beginning of sentence marker (NIT: beginning of text)
12. ✅ List four rules that fastai applies to text during tokenization.
don’t have textbook in front of me but - split on apostrophes, remove capitalization, add beginning of sentence and xxmaj (?), split punctuation
13. ❌ Why are repeated characters replaced with a token showing the number of repetitions and the character that's repeated?
not sure (repeated characters have specific meaning and can be embedded as such) 14. ✅ What is "numericalization"? converting from strings to numbers?
- ✅ Why might there be words that are replaced with the "unknown word" token?
insufficient appearances to justify an entry in the dictionary 16. ✅ With a batch size of 64, the first row of the tensor representing the first batch contains the first 64 tokens for the dataset. What does the second row of that tensor contain? What does the first row of the second batch contain? (Careful—students often get this one wrong! Be sure to check your answer on the book's website.)
hmm - the first 64 tokens of the second batch (which is different than the second 64 tokens of the first batch)
✅ Why do we need padding for text classification? Why don't we need it for language modeling? we want all of our strings to be the same length? don’t remember exactly
❌ What does an embedding matrix for NLP contain? What is its shape?
don’t really remember
(vector representations ofall tokens in vocab - has size vocab_size x embedding_size - embedding_size is arbitrary number of latent factors of tokens)
❌ What is "perplexity"? a measure - i believe something like MSE^2, i don’t remember exactly! (NIT: exponential of the loss - pretty close)
✅ Why do we have to pass the vocabulary of the language model to the classifier data block?
because tokenization is not standard / is model-specific
21. ❌ What is "gradual unfreezing"?
don’t remember (unfreezing each layer one at a time to fine-tune pretrained model) 22. ✅ Why is text generation always likely to be ahead of automatic identification of machine-generated texts?
because it is easy to tweak text generators to fool machine-generated texts / train them to evade them