Lesson #2: Deployment
(NOTE: this first appeared on Substack here)
I first read this chapter in the paper textbook before bed a few days ago, but picking up now in the notebooks. This chapter is pretty standard, more about applications of deep learning and how to think about using a model in practice. Much of it is cautionary — i.e., avoiding feedback loops, or not overtrusting the technology and keeping humans in the loop.
There’s a bunch of new functionality introduced here. For one, we’re introed to multiple ways of resizing (i.e. padding, resizing, squishing) images for training models, and to data augmentation. This stuff is already fairly familiar to me from my Computer Vision class a few years back, but fast.ai certainly simplifies it.
I just bought new plants for my room, so I decided to build a classifier based on diffenbachia, spider, and monstera plants:
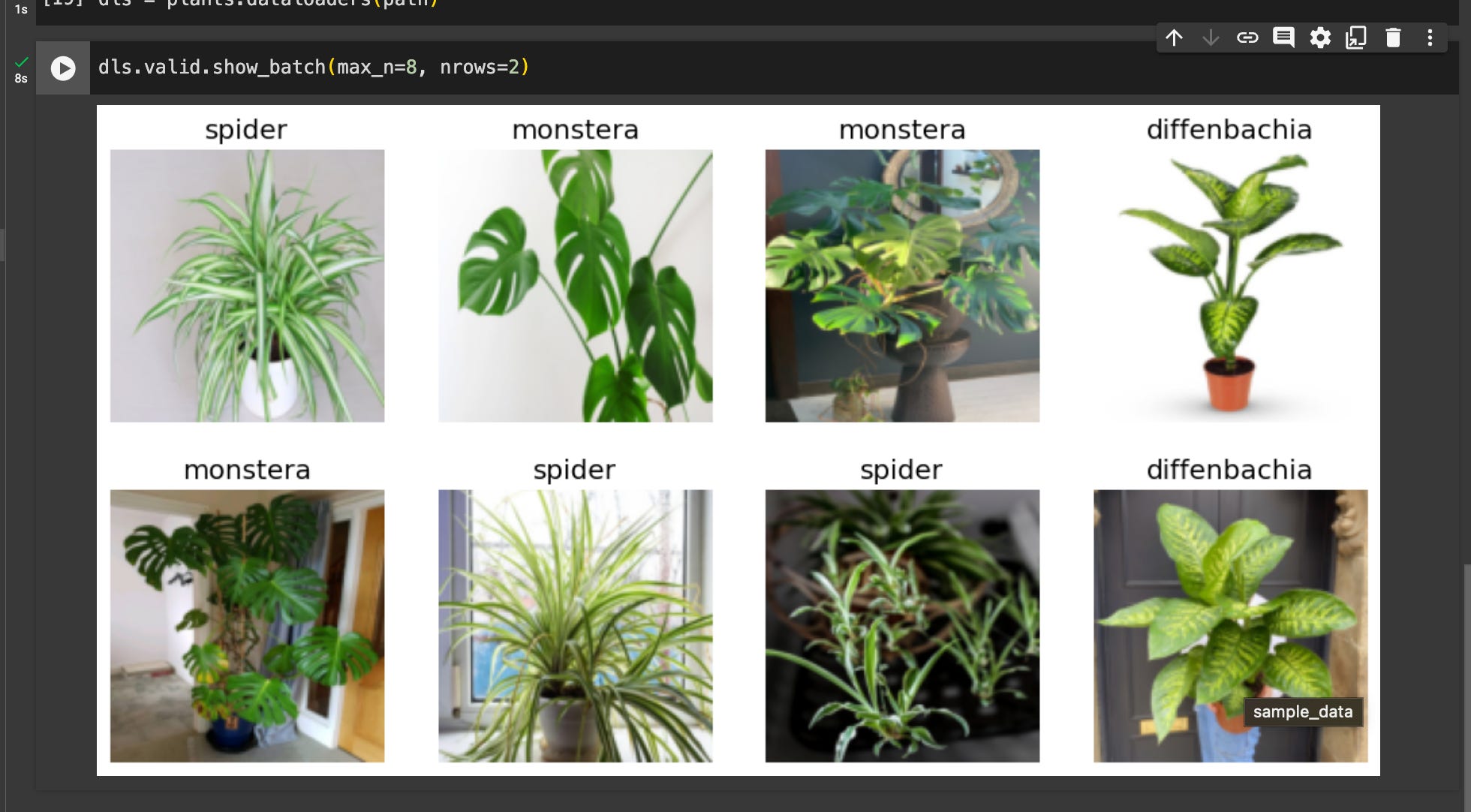
PS — one of my goals is to survey the Jupyter ecosystem as I go through this, so using Google CoLab instead of Kaggle today.
This time I’m using RandomResizedCrop, which, in each batch, crops a different part of the image. This means that, in successive epochs, it’s training on slightly different parts of the image. Cool!
The T4 GPU I have access to for free in CoLab is pretty clearly slower than the Kaggle GPUs used in the textbook; each epoch took ~20 secs, vs. 5 in the textbook. Still pretty fast either way.
One of the more interesting ideas here is that, to clean data, you should train a small model and use the images with the highest loss to weed out bad images. Here’s my confusion matrix:

Firstly I should say, this is pretty good! That said, I’m going to look at the images to see which images are causing the most trouble.
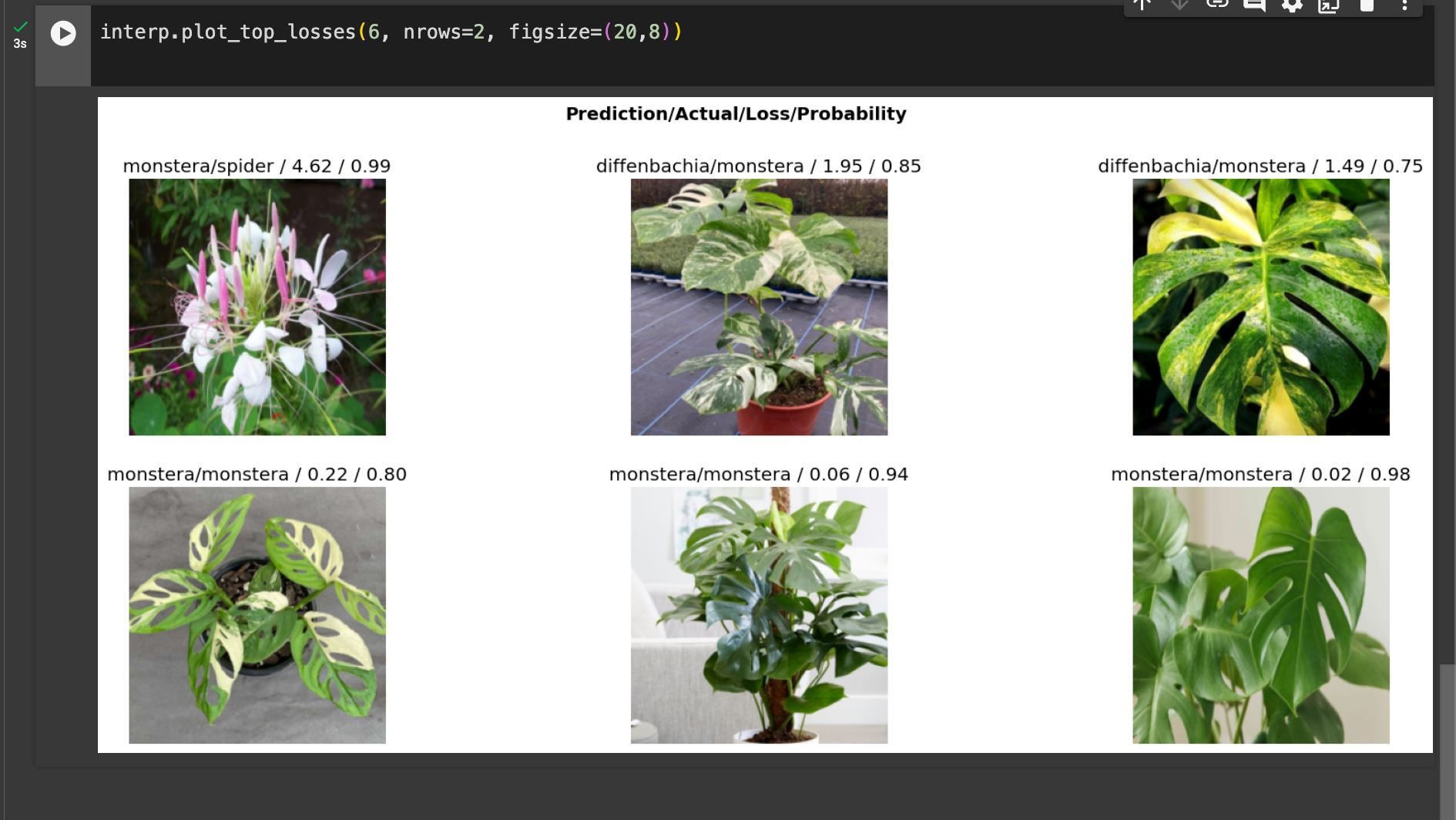
The first image, pretty clearly, is not actually a spider plant! The next two images, while both monsteras, are pretty strongly patterned monsteras, which makes sense to be confused as the diffenbachias. I’m going to remove those top 3 for convenience, which we can do using fast.ai’s handy ImageClassifierCleaner.
The textbook runs you through the steps of using Voila, a system which allows us to use IPython widgets in webapps, to make and deploy a real application.

The textbook suggests using Voila with Binder. Binder, essentially, did not work for me, and after some troubleshooting, I tried Railway. Neither of these worked for me, and neither did further troubleshooting in Binder.
It turns out that the video version in 2022 avoids this entirely by using HuggingFace Spaces and a Python package called Gradio for interface details. Most of what I see on Twitter uses HuggingFace so I figure this is just a more current approach to deployment, and satisfies the task of this lesson.
This approach worked far better for me, and I got it working locally. It classifies the diffenbachia in my room no problem!

Here’s the code I used to get that working.
app.py:
import gradio as gr from fastai.vision.all import * import skimage
learn = load_learner('model.pkl') labels = learn.dls.vocab
categories = ('diffenbachia', 'spider', 'monstera')
def predict(img): img = PILImage.create(img) pred,pred_idx,probs = learn.predict(img) return {labels[i]: float(probs[i]) for i in range(len(labels))}
title = "Plant Classifier Classifier" description = "A plant classifier I made with with fastai. Created as a demo for Gradio and HuggingFace Spaces." interpretation='default' examples = [ ["images/diffenbachia.jpg"], ["images/spider.jpg"], ["images/monstera.jpg"] ] article="
" enable_queue=Trueiface = gr.Interface(fn=predict, inputs="image", outputs="label") iface.launch()
I also have an images folder with three demo images (images/diffenbachia.jpg, images/spider.jpg, and images/monstera.jpg), my downloaded models from CoLab (model.pkl) and requirements.txt:
fastai scikit-image gradio
I uploaded all of that to HuggingFace Spaces, and it deployed my model! Success, and it works on the spider plant in my room too!
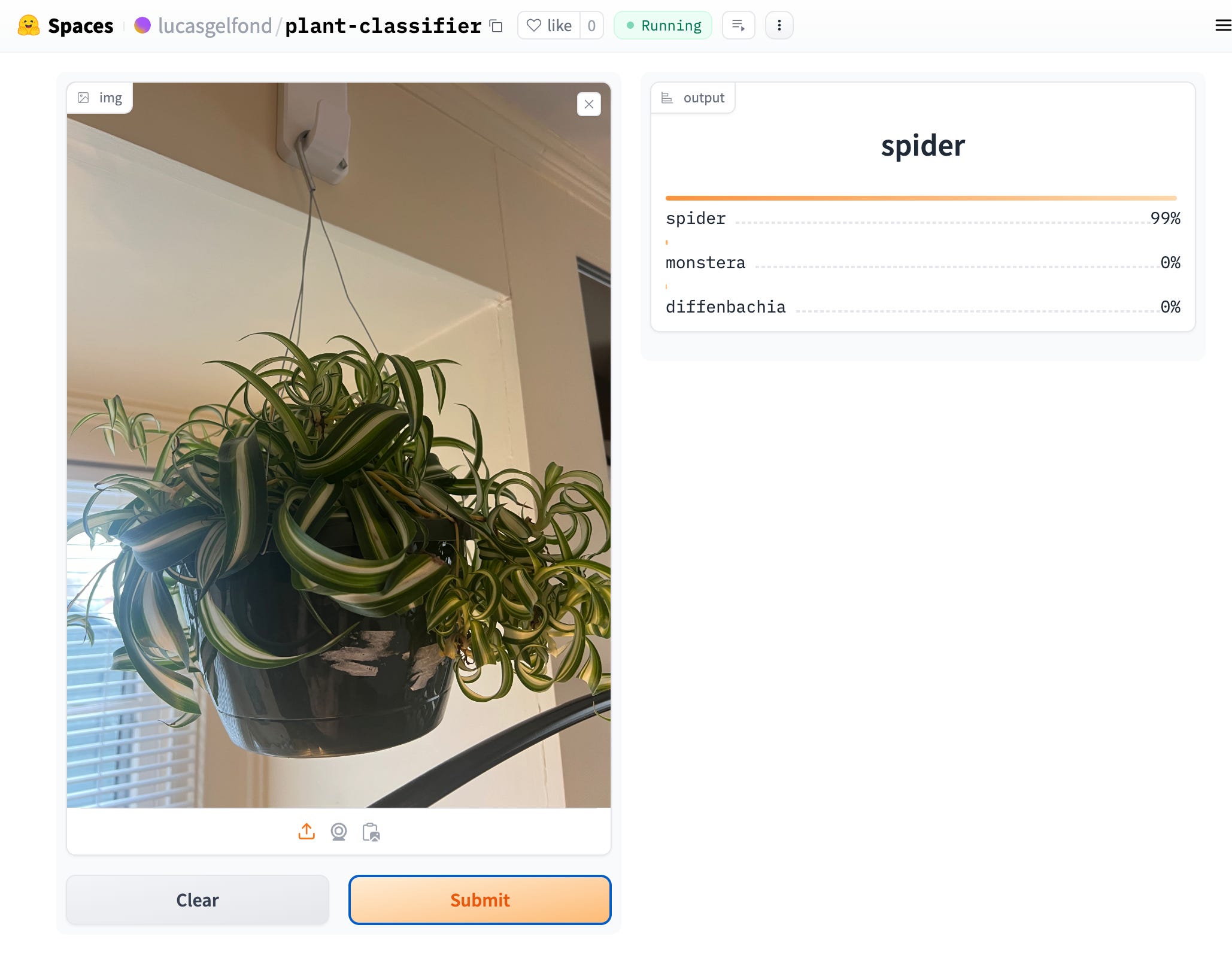
The textbook ends more or less around here, the video runs through a few more install steps, mostly to get local Jupyter notebooks installed. I spent some time trying to build an HTML single page app as they show in the video (and even trying to get something more complex using the Gradio client and Next/React) but I think some of this functionality has since been deprecated. All of the demo SPAs I found “TinyPets” are broken now, because, I think, HuggingFace made a breaking change to their API. The forum indicates this is shared experience

I’ll keep up with it, but generally my sense is that deploying to HuggingFace is also a temporary state / not something I’d ever do in production, and likely will need to brush up on these later.
For accountability, too, here’s my self-graded questions from this section:
- Provide an example of where the bear classification model might work poorly in production, due to structural or style differences in the training data.0
✅ model is trained on photos of bears from the front; in practice, most bears are seen from behind or side profile
- Where do text models currently have a major deficiency?
✅ often can include totally false information / not necessarily correct
- What are possible negative societal implications of text generation models?
✅ mass disinfo/misinfo
NOTE: missed - reinforce bias
- In situations where a model might make mistakes, and those mistakes could be harmful, what is a good alternative to automating a process?
✅ having a model still make predictions but having a human make the final call
NIT: experts!
- What kind of tabular data is deep learning particularly good at?
❌ recommendation algorithms
eh? unclear what questions are, they say “high cardinality categorical columns” - i.e. lots of discrete choices
- What's a key downside of directly using a deep learning model for recommendation systems?
✅ often it predicts what users might like, even if they’ve already seen or bought it.
- What are the steps of the Drivetrain Approach?
✅ come up with a defined objective, consider what actions to take to complete that objective, collect data, and then create a model to predict it
(this seems really dumb and sort of obvious to me!)
- How do the steps of the Drivetrain Approach map to a recommendation system?
✅ come up with objective; i.e. drive add’l sales
lever: ranking of recommendations, what can be changed by a model
data: new stuff that’s collected on consumer prefs
model: predicts recommendations for sales. maybe create two and experiment
- Create an image recognition model using data you curate, and deploy it on the web.
✅ done!
- What is DataLoaders?
✅ fast.ai’s functions that make it easiest to load files into a model
NIT- class that passes data to fast ai model
- What four things do we need to tell fastai to create DataLoaders
✅ blocks = explain the independent and dependent variable (i.e. Image →Category)
get_items = the function to get our data
splitter = how to split training vs. test data
get_y = what the labels of the data being imported are, in many cases the parent9older
- What does the splitter parameter to DataBlock do
✅ splits up data between train/validation and test
- How do we ensure a random split always gives the same validation set
✅ we use the same random seed!
- What letters are often used to signify the independent and dependent variables?
✅ x, y
- What's the difference between the crop, pad, and squish resize approaches? When might you choose one over the others?
✅ crop will use only a section of an image
pad will add 0s / black on edges of an image
squish resize will squish it down across some axis to make it fit
you might choose crop, for example, if you are looking for partners or things where all of the image doesn’t matter, it’s really just based on the sort of images you have
- What is data augmentation? Why is it needed?
✅ data augmentation creates “fake” data based on stuff we have. for example, in images, data augmentation would slightly rotate things, generate darker/lighter images, etc, ways of introducing variation at will help us solve corner cases and not overfit to (often small) datasets
- What is the difference between item_tfms and batch_tfms?
❌ the former runs on each item, where the latter runs only once per batch / all at once
NOTE: yes, but, moire significantly, item runs on the CPU, batch done on e GPU, batch_ttfms are more efficient than the individual ones
- What is a confusion matrix?
✅ shows what labels were predicted for wrong; i.e. shows actual on x axis and predicted on y axis. the diagonal indicates correct predictions (predicted = actual)
- What does export save?
✅ model weights!
NIT: architecture, trained parqameters, and how dataloaders are defined
- What is it called when we use a model for getting predictions, instead of training?
✅ inference
- What are IPython widgets?
✅ small things we can add in notebooks to make them interactive to people beyond the immediate notebook. includes things like VBox for organization / styling and other components which can create a basic frontend
- When might you want to use CPU for deployment? When might GPU be better?
✅ most inference tasks only need a CPU. GPUs are good if you are running a ton of classification tasks in parallel. CPUs have fewer lockup issues and are usually more available
- What are the downsides of deploying your app to a server, instead of to a client (or edge) device such as a phone or PC?
✅ There might be more latency (in addition to processing, sending information up and down), no ability to be offline, privacy risks
- What are three examples of problems that could occur when rolling out a bear warning system in practice?
✅ images of bears online are insufficient; i.e. most are from the front, don’t cover bears in low light, etc
low resolution camera images from the site
results may not be returned enough in process
- What is "out-of-domain data"?
✅ data that our model sees in production but that is essentially missing in training
- What is "domain shift"?
✅ data a company sees changes over time; i.e. looking at different problems / scenarios than when you began, and thus new preds are not accurate
- What are the three steps in the deployment process?
✅ manual process
limited scope deployment
gradual expansion