(NOTE: this first appeared on Substack here)
Lesson 1 was pretty standard, mostly just running through all of the details of the fast.ai library, how it interacts with pytorch, etc. My biggest takeaway is that fast.ai gets rid of a lot of the really annoying tasks in training; i.e. exposing functions like DataLoaders, those which do image augmentation, standard datasets accessible by path, and generally just setting really smart defaults constrains the problem a lot and makes it easy to pick up.
There's some stuff in here that's broadly foundational in deep learning, and general explanations of types of models, i.e. those that deal with images, text, and tabular data. I've only experienced vision before, in a Brown course called Computer Vision, so some of this is new.
The initial first project is a bird classifier. I used the stripped Kaggle notebook to build a cat-and-dog classifier.
Note that in order to use search_images_ddg, an image searcher with DuckDuckGo mentioned in the video that doesn't require any credentials (unlike the default search API that requires a key from Azure's Image API) you need to also install fastbook
!pip install fastbook duckduckgo_search
I got pretty poor classifications originally on the cat and dog classifier, mostly, I think, because those terms are too generic. Some of my training data was really, really bad:

I tried another comparing spongebob_or_patrick that also wasn't great, because many of the photos included both characters.
I had to try a few more examples before I got something that worked. Eventually I came to "headphones vs. earbuds." I guess maybe some earbuds could be considered headphones (and I'm doing this notebook after reading Chapter 2, where there's stuff about better cleaning data) in search results, but the data look pretty good to me.

I'm getting a little bit of an 'opposite day' situation here, great but opposing results. My guess is just that I should swap this to 'is_earbud,' which I did. Running with a photo of headphones on my desk, it works!
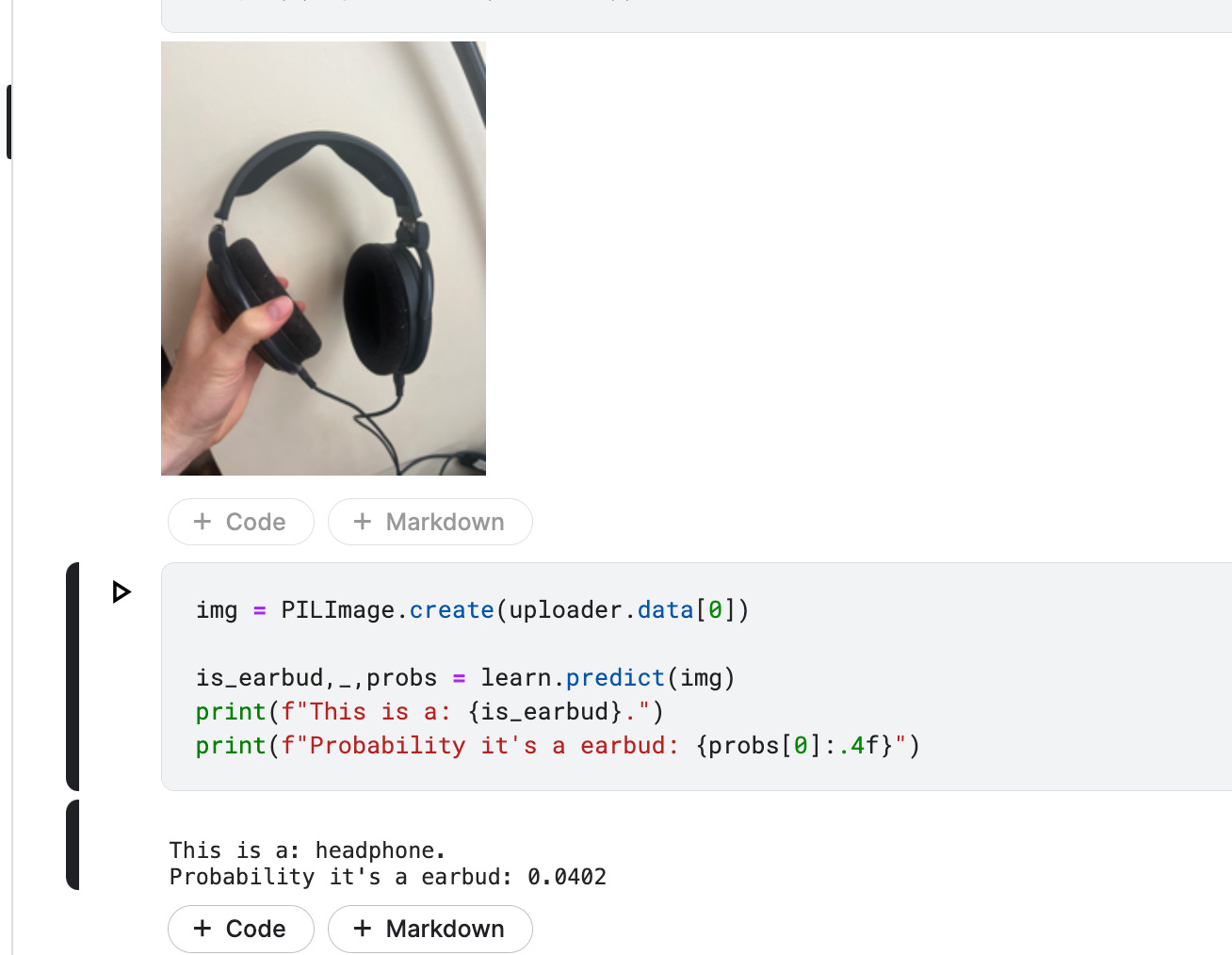
And, for good measure, testing with a pair of earbuds on my desk:

Success again! Pretty cool!
I worry about being too passive in this course, so I typed out and graded all of my responses to the questions at the end of the chapter. I'm including my (really brief) responses with a green checkmark or red "X" emoji. Perhaps useful to see what I got and missed:
✅ Do you need these for deep learning?
Lots of math T / F
Lots of data T / F
Lots of expensive computers T / F
A PhD T / F
none of the above
- ✅ Name five areas where deep learning is now the best in the world.
speech recognition
medicine
folding proteins
product recommendations
go
- ✅ What was the name of the first device that was based on the principle of the artificial neuron?
Mark I Perceptron
- Based on the book of the same name, what are the requirements for parallel distributed processing (PDP)?
set of processing units, state of activation, output function, pattern of connectivity, propagation rule, activation rule, learning rule, environment
- ❌ What were the two theoretical misunderstandings that held back the field of neural networks?
NOTE: XOR gatges!
only adding one layer of neurons - made them too big and slow
initial beliefs of limitations about addition of more layers
- ✅ What is a GPU?
graphical processing unit
- ✅ Open a notebook and execute a cell containing:
1+1. What happens?2
- ✅ Follow through each cell of the stripped version of the notebook for this chapter. Before executing each cell, guess what will happen.
yes
- ✅ Complete the Jupyter Notebook online appendix.
- ✅ Why is it hard to use a traditional computer program to recognize images in a photo?
impossible to explain intuitions
- ✅ What did Samuel mean by "weight assignment"?
setting parameters; changing the values in diff neurons based on how well they are validated
- ✅ What term do we normally use in deep learning for what Samuel called "weights"?
parameters
- ✅ Draw a picture that summarizes Samuel's view of a machine learning model.
weights reassigning themselves
- ✅ Why is it hard to understand why a deep learning model makes a particular prediction?
because it's difficult to visualize weights normally; weights can represent really complex internal stuff
- ✅ What is the name of the theorem that shows that a neural network can solve any mathematical problem to any level of accuracy?
universal approximation theory
- ✅ What do you need in order to train a model?
data
parameters
labels / loss function
- ✅ How could a feedback loop impact the rollout of a predictive policing model?
model trains on existing data
model thinks of sending more police to areas that are heavy in arrests
- ✅ Do we always have to use 224×224-pixel images with the cat recognition model?
images need to be the same size to be processed; 224 is an artifact of an old model
- ✅ What is the difference between classification and regression?
putting something into a category label vs. giving it a numerical value
- ✅ What is a validation set? What is a test set? Why do we need them?
validation set is used to train a model and improve its weights
test set is used to evaluate at the very end; doesn't change the model
important because often, in training, the model will essentially memorize the validation set / overfit to it, vs. being able to generalize
- ✅ What will fastai do if you don't provide a validation set?
automatically segment part of the training data out, by default 20%
- ❌ Can we always use a random sample for a validation set? Why or why not?
CORRECTION: no! for time series, use just the end
yes but we need to use the same seed. if we don't use the same seed / keep the data in the validation vs. training set, we'll train on it and will essentially memorize the validation set
- ✅ What is overfitting? Provide an example.
i could draw it out but basically; we pick up on things that are too specific in the training set vs. gaining genrealizable things. basically we learn how to recognize the exact examples in validation set vs. things beyond it; we "memorize" the examples instead of the patterns
- ✅ What is a metric? How does it differ from "loss"?
loss is usually stochastic gradient descent; things that are good for automatically updating weights
metrics are for human consumption
- ✅ How can pretrained models help?
they are mostly trained and work on relevant examples!
lots of tasks are the same across many examples, and allows us to use smaller training sets to finetune
- ✅ What is the "head" of a model?
last layer that is added for classification in the dataset
- ✅ What kinds of features do the early layers of a CNN find? How about the later layers?
usually the most general; edges, corners, etc
later layers are way more complex
- ✅ Are image models only useful for photos?
nope! can make other things into images, like audio waveforms and stuff
- ✅ What is an "architecture"?
NIT: structure
the configuration of the neural network; i.e. the number of layers, how densely connected they are
- ✅ What is segmentation?
models that can recognize the content of every individual pixel in an image
- ✅ What is
y_rangeused for? When do we need it?the possible range for our target
used for tabular tasks, when we are using a regression model
- ✅ What are "hyperparameters"?
"parameters about the parameters" - i.e. number of layers, number of weights, etc
- ❌ What's the best way to avoid failures when using AI in an organization
use a test set!
NIT: simple baseline metric to beat!